


[ad_1]
In AI, combining large language models (LLMs) with tree-search methods is pioneering the approach of complex reasoning and planning tasks. These models, designed to simulate and improve decision-making capabilities, are increasingly critical in various applications requiring multiple logical reasoning steps. However, their efficacy is often hampered by a significant limitation: the inability to learn from previous mistakes and frequently repeating errors during problem-solving.
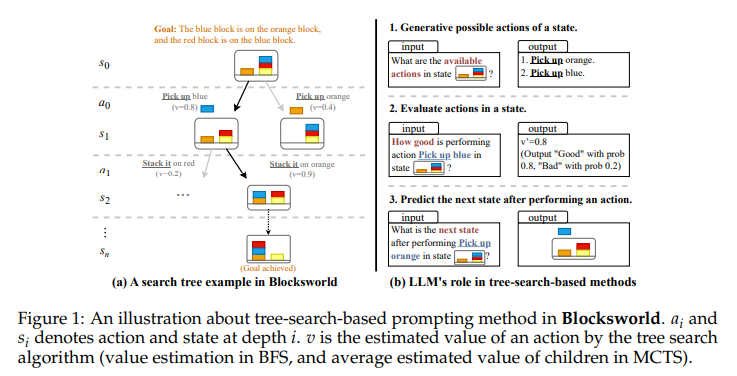
A prevalent challenge within AI research is enhancing LLMs’ problem-solving accuracy without manually reprogramming their underlying algorithms. This challenge is especially pronounced in tasks that involve extensive planning and reasoning, such as strategic game-playing or complex problem-solving scenarios where each decision impacts subsequent choices. Current methods, such as breadth-first search (BFS) and Monte Carlo Tree Search (MCTS), while effective in navigating these problems, do not incorporate learnings from past search experiences.
Researchers from the School of Information Science and Technology, ShanghaiTech, and Shanghai Engineering Research Center of Intelligent Vision and Imaging introduced a novel framework called Reflection on Search Trees (RoT). This framework is specifically designed to enhance the efficiency of tree-search methods by allowing LLMs to reflect on and learn from previous searches. By integrating a robust LLM’s capability to analyze past tree search data, RoT generates actionable guidelines that help prevent the repetition of past mistakes. This innovative approach leverages historical search experiences to bolster the decision-making processes of less capable LLMs.
The methodology behind RoT involves the sophisticated analysis of prior search outcomes to formulate guidelines for future searches. These guidelines are meticulously crafted based on key insights from analyzing actions and their consequences during past searches. For instance, in complex reasoning tasks across various tree-search-based prompting methods like BFS and MCTS, the introduction of RoT has significantly enhanced LLM performance. In practical applications, such as strategic games and problem-solving tasks, RoT has demonstrated its capability by improving search accuracy and reducing repeated errors.

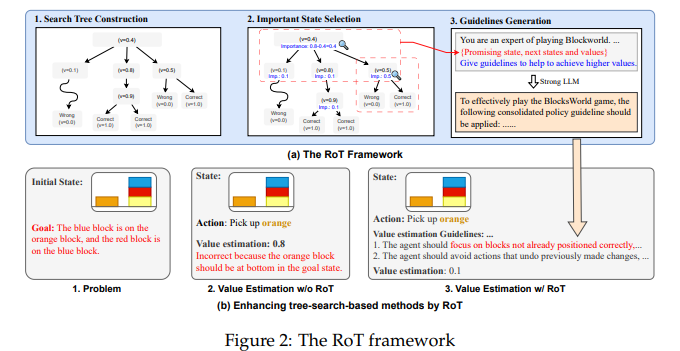
The effectiveness of the RoT framework is further underscored by its substantial impact on performance metrics. For example, in tasks that employed BFS, the accuracy improvements were quantitatively significant. In more challenging scenarios requiring a higher number of reasoning steps, RoT’s benefits were even more pronounced, illustrating its scalability and adaptability to different levels of complexity. Notably, RoT’s implementation led to a measurable reduction in the repetition of errors, with experimental results showing a decrease in redundant actions by up to 30%, streamlining the search processes and enhancing overall efficiency.
In conclusion, the Reflection on Search Trees framework marks a transformative development in utilizing large language models for complex reasoning and planning tasks. By enabling models to reflect on and learn from past searches, RoT improves the accuracy and efficiency of tree-search-based methods. It extends the practical applications of LLMs in AI. This advancement highlights the critical role of adaptive learning and historical analysis in the evolution of AI technologies.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
[ad_2]
Source link

Be the first to comment